前幾天實踐了將Kong 以及API的Log導入了Elasticsearch,也成功地可以使用Kibana來觀看不同角度的Log。接著筆者準備要帶讀者來探索可觀測性的第二根柱子,trace。
筆者過去在DevOpsDays 不斷的聽到可觀測性的議題,但老覺得有點難以捉摸。原因是,筆者所在的企業中,幾乎都是使用VM建置服務,因此對於連續追蹤的議題就較無接觸。
但其實可追蹤的議題就就像下水道工程,平常你不會去在意管線如何佈設、水流如何分流,因為一切都在正常運作。但一旦下起大雨、馬桶倒灌或是某處堵塞時才會驚覺「如果沒有當初那套完整的排水系統,後果會有多嚴重」。Trace 在系統裡的角色就是這樣──它平常默默收集各個服務、各個 API 呼叫之間的路徑與時間,但只有在問題發生時,你才會發現它的重要。
舉個例子,假設一個使用者抱怨系統很慢。沒有 Trace 的時候,你只能看個別服務的 log,猜測是不是資料庫查詢太久,還是 API Gateway 卡住。團隊往往需要花上好幾小時,甚至幾天的時間才能定位問題。但有了 Trace,就像擁有一份「管線地圖」,能清楚看到 request 從使用者入口一路走到後端各個微服務的完整流程,哪個環節延遲、哪個服務異常,一目了然。
這也是可觀測性三大支柱中,Trace 的獨特價值:它提供了一條「路徑視角」,讓我們不再只是看單點,而是看整段旅程。雖然建立 Trace 機制需要額外的努力,例如在程式碼中注入 Trace ID、串接像 OpenTelemetry 這樣的框架,但當系統真正發生瓶頸時,它能大幅縮短問題定位時間,避免團隊陷入「各說各話」的混亂狀態。
接下來,筆者將透過 Kong 的opentelemetry plugin 以及dotnet api 程式的實踐,將trace的資訊,透過OpenTelemetry Collector 以及Jaeger Collector 蒐集到前幾天建置起的elasticsearch中,並透過Jaeger Query來追蹤每一個請求的路徑。
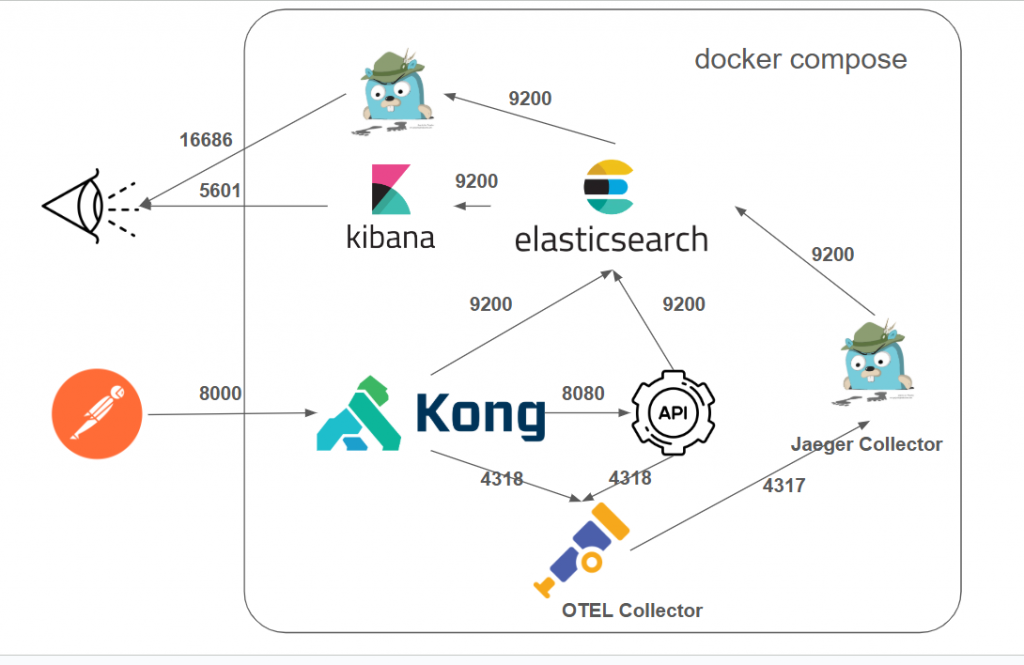
圖10-1 架構圖
這次的架構將基於前一次,並延伸出幾個不同的角色來實踐可觀測性,可以參考圖10-1 ,簡單介紹各個角色如下:
http://localhost:8000/my-service 發送請求。kong.yml 的設定,將請求轉發到後端的 .NET API。http-log Plugin,將每筆請求的紀錄發送到 Elasticsearch。opentelemetry Plugin,將追蹤資料發送到 OpenTelemetry Collector。Serilog 將結構化的日誌直接寫入 Elasticsearch。OpenTelemetry SDK 將追蹤資料發送到 OpenTelemetry Collector。首先先來關注到這次的範例專案,首先先來看ironman2025\case_ELK_Jaeger\docker-compose.yaml,並節錄部分本次新增的部分來說明,預計使用今明兩天的篇幅來說明。
聰明的讀者如你,應該還記得前兩天因為Kong 寫Log 到Elasticsearch預設沒有timestamp這個欄位,因此需要手動到Elasticsarch中建立一個ingest pipeline,來將日後的Kong Log可以正確處理started_at這個欄位的時間格式。
由於手動建立這件事情實在很不符合筆者原則,因此為了處理這個痛點,另外在docker compose 的yaml中撰寫了下面的服務,以協助在elasticsearch啟動之後,自動地去建立ingest pipeline。這樣就不用手動建立啦!
kong-init:
image: curlimages/curl:8.8.0
container_name: kong-init
command:
[
"sh", "-c",
"until curl -s http://elasticsearch:9200; do echo 'Waiting for elasticsearch...'; sleep 2; done; \
curl -XPUT 'http://elasticsearch:9200/_ingest/pipeline/kong-timestamp-pipeline' \
-H 'Content-Type: application/json' \
-d '{\"processors\":[{\"date\":{\"field\":\"started_at\",\"formats\":[\"UNIX_MS\"],\"target_field\":\"@timestamp\"}}]}'"
]
networks:
- kong-net
depends_on:
- elasticsearch
可以關注到,在kong-init這個容器,取用了官方的 curl 容器映像。並且在啟動時執行一個shell指令,內容分兩段:
1. 等待 Elasticsearch 啟動
until curl -s http://elasticsearch:9200; do echo 'Waiting for elasticsearch...'; sleep 2; done;
這段會不斷嘗試連線到 elasticsearch,直到服務可用才繼續往下執行。
2.建立 ingest pipeline
curl -XPUT 'http://elasticsearch:9200/_ingest/pipeline/kong-timestamp-pipeline'
-H 'Content-Type: application/json'
-d '{"processors":[{"date":{"field":"started_at","formats":["UNIX_MS"],"target_field":"@timestamp"}}]}'
這個指令會在 Elasticsearch 建立一個名為 kong-timestamp-pipeline 的 pipeline,內容是把 log 裡的 started_at 欄位(UNIX 毫秒格式)轉換成標準的 @timestamp 欄位。
這個行為就跟之前筆者發現timestamp沒有資料,手動去新增一個ingest pipeline一模一樣。
接下來,明天來一起探討其他新增的docker compose中的其他服務。今天很晚了,我們明天見~~
也可以選擇在 kong.yaml 設定 @timestamp 欄位,提供參考~
例如:
plugins:
- name: http-log
config:
http_endpoint: http://host.docker.internal:9200/kong-logs/_doc
method: POST
content_type: application/json
custom_fields_by_lua:
'@timestamp': "local ms = kong.request.get_start_time(); if ms then local sec = ms / 1000; return os.date('!%Y-%m-%dT%H:%M:%S', sec) .. string.format('.%03dZ', ms % 1000) end; return nil"
喔!!這好酷喔,感謝感謝~!!又學到一招~
果然網路上高手真多~


 iThome鐵人賽
iThome鐵人賽